
Code Reviewing an AI Code Editor
Great functionality, but does not quite live up to the hype

I started trying out Cursor a few weeks ago. Normally I don't concern myself with jumping at the shiniest new thing, but I have a problem that I've been hoping LLMs could solve.
For years, I found myself spending more time debugging production issues at scale than writing new code. That changed how I wrote code to optimize for maintaining it on production. Production issues tend to be easier to debug with fewer abstractions. One of those abstractions is ORMs. There are a few benefits from not using one:
1 - It is a lot easier to find the code that generates a query that ends up in a slow query log when the query is in the code versus an ORM.
2 - ORMs make it really easy to create queries that join tables without having the developer think about the nuances of the join. That results in fewer options when the database needs to be sharded.
3 - At some point, database tables get big. Being able to run migrations and rollback migrations with an ORM is nice, but the mechanism becomes unuseable with big tables. Adding a column to a table with a lot of rows causes a table lock, which makes every user request wait for that operation to complete. Not so bad when the migration takes half a second. Much worse when the migration takes 30+ seconds. Not using an ORM forces you to pay attention when running migrations and notice when migrations are going to require more than just a simple query to add a column.
4 - Writing a query is simple whereas every ORM has their own quirks and nuances. The number of abstractions can make those quirks difficult to work around. Example: the last time I used mybatis was in 2015 and it was littered with silent errors.
Not having an ORM means I have a lot of code (thousands of lines) with handwritten queries. That may make it easier to deal with in production, but building new features is a bit slower and a lot more painful.
That's just one practice. I've got a lot more and they all make the same trade-off: write a lot more code upfront to make it easier to deal with in production later. I've long wished that IDEs could create an auto-complete that was good enough to remove the negative in that trade-off. AI code editors like Cursor may finally be granting that wish. It does... to a point. I'll be using it consistently going forward, but the productivity boost only comes if you focus on using it on things it is good at.
In this post, I'm going to review the code that Cursor has generated. I'll be looking at code generated by both the Tab (auto-complete) and the Agent features in Cursor. Both will be used in the context of an existing code base stored as a monorepo. I'm thinking of doing another review of a 100% Cursor generated app in another post.
Let's cover the Agent first before moving over to Tab.
The first thing I tried with the Agent was to generate all the CRUD queries for some new database tables I was adding. It did a really great job here. All I needed was to point it at the file with the schema and it created a file that had all the interactions I needed. My notes on the code itself:
the Agent took into account that I used a wrapper around the mysql library
the Agent recognized that I used soft-deletes in those tables and modified the queries accordingly
the Agent noticed which tables had a 1-1 relationship and which had a 1->many relationship and had all the queries take that into account
the Agent accounted for the lookup tables I had defined
The most common issue I noticed was that the Agent was making assumptions of what I named things in my wrapper rather than check the wrapper file to see whether they actually existed or not. It ended up calling a select() function when that function did not exist (I have query_primary() and query_replicas() instead). That was really easy to fix so not a big deal.
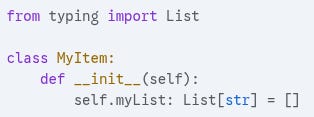
A bigger issue is the tendency to use mutable default arguments in Python. Example:

This results in myList being a shared variable across all instances of MyItem. Create 3 instances of MyItem and giving them all different values for myList will result in all 3 instances having the same list of values.
If you need a default value, it should be defined in the constructor.
At first, that didn't seem like a big deal. It's an easy fix to make.
The problem was when I needed to remove a primary key from a database table. I realized I had created an auto-generated primary key out of habit, but the table had a unique key that would work as the primary. That auto-generated column was redundant. I tried asking the Agent to remove the primary key and replace it with the column that was a unique key. One of the things it did was replace the fix I had on the default value of a list with the mutable default argument it had created earlier. You can usually accept/reject changes that Cursor made, but the changes I wanted were grouped with the changes I didn’t.
I might have been able to resolve this with cursorrules, but it demonstrates a lack of understanding of how memory works in Python.
The Agent also did a whole host of other things that did not make sense. 6 other columns were deleted from the table. A file was generated on the frontend with code that basically did nothing. Little of the code that needed to be updated to account for the change in primary key was actually updated. That goes down to none when taking into account that I had to reject all the changes because of the issues listed above.
Now let's go to how well the Agent can generate frontend code. For context: I use a modified version of Flux, Atomic Design, and BEM. That trade off I mentioned? The good part is that for almost 10 years, I have never needed to spend more than 10 minutes debugging a frontend issue. The exceptions are the handful of times I got lazy and deviated from that pattern.
The reason being lazy is so tempting? I once added a button to a form and had to modify 12 files. That's a big negative that I was hoping AI could remove.
I wanted the Agent to generate all the frontend code for listing a bunch of elements and opening up an edit form to modify those elemnts. Unfortunately, generating a full frontend feature was less successful. There were a ton of small issues (like using Enum values that did not exist), but there was one big one that caused me to give up on using the agent this way. I could not get the Agent to understand how the architecture worked. The agent accounted for the uni-directional nature of flux (View -> Actions -> Datastore -> View) in the edit form, but it would fail to generate the actions or the datastore. It just called functions that sounded right, but did not exist.
Trying to get it to finish the implementation only resulted in garbage that I had to throw out. I tried various ways to tell the Agent how this architecture worked with Cursor rules, but none of it worked.
On top of that, setState() was called redunantly on the same data many times. This wasn't because the Agent wrote setState() calls, but it didn't understand how the flux dispatcher worked and called setState() in situations where the dispatcher had already triggered one.
My guess on what happened here is the nature of the training data. For instance, Flux is not a framework. There is no Flux package that you can install and have things happen. You have to write your own dispatcher. That didn't seem like a big deal to me given how many times I've implemented the observer pattern in the past, but apparently it was a sticking point for a lot of people. That means fewer projects using Flux and more projects using something like Redux.
Related to that is that most developers prefer to optimize for the upfront writing of code rather than the maintenance of code. That means there were few, if any, projects that use a similar architecture to the one I use (though I will admit that my choices are a bit extreme). LLMs just don't have the training data to account for this.
Another thing I was hoping AI could help with is writing automated tests. Writing automated tests is easy, but it is incredibly tedious. That's likely the real reason many projects don't have sufficient testing. So I asked the Agent to write some test cases. It honestly did a phenomenal job writing Python tests. It accounted for the fact that I had very few unit tests and that most of the tests used real data in the database. It used my pattern of preventing data collisions between tests without me having to tell it. The Agent also seemed to differentiate between tests that should have been unit tests (e.g. datetime manipulation) vs system tests. One slight drawback was that it did test for every edge case, even the ones that really didn't matter, but those were easy to delete.
Writing new tests was great, but fixing tests proved more difficult for the Agent. I had a bug with a parser for ISO 8601 duration strings. I assumed the bug was with the code and not the test. I was wrong, but the Agent failed to catch that. It did exactly what I asked and changed the parser code. Those changes were largely useless as the logic was still the same.

The frontend tests generated by the Agent were completely useless. There's little point in describing every single issue because in the end they didn't test any of the logic I needed to test and none of the tests that were generated passed. There was no point in even cleaning them up.
Given these failures, I expected my next attempt to also fail, but I wanted to see what the Agent would come up with anyway. I have the UI displaying a nested list of items. I wanted to change the deepest level to go from individual items to an aggregate of another field. This would have required changes in the backend and the frontend because even though the aggregated field had data stored in the database, it wasn't being returned to the frontend in any API call.
The Agent assumed that it was and made up class variables that had the aggregated field's name. Those variables were never set. I tried telling the Agent that it needed to modify the backend code. It made some changes to the backend, but it never actually sent them in the API call and still never set the variables on the objects in the frontend. The interesting thing is that the Agent explicitly states that it needed to modify a file that contains the business logic, but it never does.

Overall, the Agent removes a lot of the tediousness of a good chunk of Python code. Anything more complex than simple test cases or CRUD functions seems to be beyond it. I could have spent more time trying out different prompts to see if it could do better, but I already spent more time trying than it took to just write a lot of the code myself. That gap also increases when taking into account Tab.
The Tab functionality is where Cursor really shines. For years, I have been wishing for a better auto-complete in IDEs. I've tried creating all sorts of templates for boilerplate code, but it always ends up taking more time than just writing the code manually. Tab is that auto-complete I have been wishing for.
There are a whole host of things it can do. I'll start with the feature where if you type a new class variable, you can just hit tab as it adds that variable to function calls and instantiations. If the class has a DB table associated with it, hitting tab will add it to the queries. Does it save that much time than typing all that code manually or using a traditional IDE's auto-complete? Not really, but it *feels* great. We should not discount getting joy from writing code. The strange thing is that Tab is less process intensive than the Agent (you have monthly limits on the Agent, but not Tab), but it does a much better job of dealing with schema changes.
Start typing an if statement, and Tab will attempt to fill in the logic based on the condition set as well as the else if and else blocks. It only gets this right if the logic is simple, such as whether to display an frontend component based on a variable or showing a loading/empty component.

This is also not a ton of time saved (~10 seconds maybe for real code), especially when you include reviewing it, but it *feels* great.
It also does a decent job of taking into account the context of the code as a whole. Have an enum in Python that you also need in Typescript? Type the first few letters of the enum's name and Tab will finish writing the enum for you. Creating a new frontend class that gets instantiated from the JSON in an API response? Create a file in the frontend with a similar name to the class in the backend and Tab will write the class for you with the conversion from the JSON data.
Tab also accounts for the style of the code, such as how I require Sass files. All I need to do is create a file with the name of a component and Tab will finish creating the boilerplate. With React, this means it writes the imports, a custom State type, a custom Props type, and all the other component boilerplate. Tab is simpler than the Agent so it certainly doesn't understand my frontend architecture, but it can follow the pattern of my code enough to write the code necessary for the flux dispatcher to do its thing.
Tab is not perfect though. Sometimes it will recommend nonsensical things. I've had it create an if/else statement with a nested if that ignores a common condition. I've had it try to write logic that it seems like I may need based on the names of functions, but my logic is more complex than it is capable of.
It will attempt to finish code based on a pattern, but it determines that by trying to find patterns in the language and not understanding the true context. In the example below, I was typing a list of our firm's services. As soon as I typed the first few letters of the first mapping, it started making suggestions. Because I started with "Systems Integration", it automatically gave me suggestions that made sense for a dev shop and not an accounting firm. Once I started typing in accounting terms, it tried to fill the rest with synonyms regardless of whether they made sense or not.

Like the Agent, Tab also does not generate an abstract syntax tree of the codebase for reference. It makes guesses based on the naming of the existing code. That often results in it calling functions that don't exist, using enums that don't exist, attempting to set class variables that don't exist, etc. It can also mess up your imports.

The biggest problem with Tab is not that it makes these mistakes. It is that it can sometimes be hard to tell what it is about to change and that it will sometimes change code that is off screen. This isn't so bad if you're changing existing code because you can look at the Git diff. It is a lot worse with new files. Rather than let it do it's thing and modifying it, I often have to tell it not to write anything. This is even if I want a handful of the lines it suggests, but not the other 80% of the suggestion. All the time savings it provides would go away if I spent it reviewing some of its more ambitious suggestions.
Overall, I love using Cursor. It definitely isn't the 10x boost some people claim. I've found it to be a 5% - 10% boost when you add up the sum of every individual instance where it saves time. That may improve as I develop a better sense of what it is good at and what I should avoid using the Agent or Tab for. The important thing to note is that many things are more than the sum of their parts. Remember how I mentioned that Tab didn't save me much time on some operations, but they all felt good? That changed the tasks I had from being menial and boring to being interesting. I could focus on the actual logic of the code rather than splitting my focus with typing a bunch of boilerplate. Increased focus and having more fun doing the work bumps the productivity boost to 10%-20%, which more than justifies the subscription.
If you're using an AI code editor right now, I'd love to hear about things that you've seen it do well versus the things it does poorly. It's always good to see more examples.