
Some Past Software Development Posts I Want To Revisit
Some oldies but goodies

I've written a lot about software development over the years. I'm big on constantly learning so my position on certain things has changed. Here are some posts on technical topics that I would like to revisit soon:
Engineers worry a lot about performance and scalability, but these are not the same. Performance is how well our software runs at given conditions such as number of users in the system. Scalibility is how well our performance adapts to a variety of conditions. Another way to put it is that performance represents a point in time while scalibility is the slope of all the performance points over time.
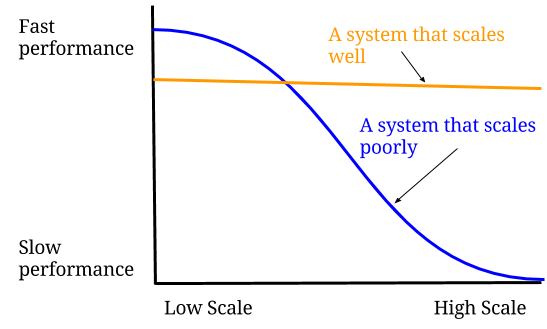
One of the hardest things to understand is that getting a system to scale often means adding overhead that lowers performance at low scale. This is often an acceptable trade-off.
I think a lot about low scale and high scale. I almost never think about mid-scale as it is just a stepping stone. The issue is that a lot of programming practices involve optimizing for mid-scale. This habit comes from a time when scaling meant getting as much traffic to run on a single server as possible. The growth of software use and the size of software systems makes that notion less relevant than it once was. Scaling today is about getting to a point where you can add more servers easily.
I still see a lot of code that is difficult to work with because performance tuning was added with the mindset of getting more scale out of a single server. Unfortunately, you can't just grow from code that's optimized for mid-scale into code that's optimized for high scale. The concepts are fundamentally different.
Example: Mid-scale means optimizing database queries to minimize the amount of queries and the amount of time each query takes. When you hit high scale, you need to consider sharding the database onto multiple servers. Queries optimized for mid-scale tend to be complex and limit your options on how you can shard. This often means those queries have to be completely re-written as well as all the code that depends on those queries.
The post I'll write on this topic will explore further issues with optimizing for mid-scale.
Solving Common Concurrency Problems
"The first rule of distributed systems is to not build a distributed system."
That quote was printed on the first page of my distributed systems textbook from college. Taking that quote at face value would be absurd because the entire internet is effectively a distributed system. The quote is trying to make us understand that we should not make software development any harder than it already is. We often tackle engineering problems head on when it is often easier and better to avoid the problem.
The same could be said for building concurrency into software systems. In that post, I describe solving a concurrency problem by removing concurrency as an issue. The only cost was a bit more data in the database.
Concurrency is becoming more and more unavoidable, especially at high scale. If I rewrite this post, I'd focus more on why concurrency is often necessary and how to mitigate the risk of adding it to a software system.
Switching Costs in Software Development
I often feel like an old man yelling at the clouds on this topic. Many people think I'm crazy when I only use AWS services that are also provided by GCP or Azure and easily transferrable. This rules out a lot of serverless options such as Lambda or AppEngine as switching from one to the other involves rewriting quite a bit of code.
The need to switch from AWS to something else is unlikely in the near term. Then again, so was the need to switch from VMare and a lot of companies are realizing the cost of vendor lock-in the hard way. All it takes is for a new CEO, an activist investor, a merger, or some other change at the top for everything about a service to change. I once worked at a company with a VMware-like event, though we were a lot smaller and so was the vendor. It still made it a lot harder for the company to make payroll.
The problem with my position is that the complexity of services are making many of them distinct and without an easy replacement. Example: if you rely on the Google Maps API, switching to OpenStreetMap or Apple Maps is not going to be seamless. The code may not need to change much other than switching the endpoint and parsing the response differently, but the results from those services will differ greatly. That results in a huge impact for users. What's the alternative though? If you have an application that needs maps, you're going to use a third party API. Building your own maps is unfeasible for anyone but big tech (and look how hard it was for Apple to get it right).
Sometimes switching costs are unavoidble, but we can still make contingency plans. If I rewrite this post, I'd focus on what those contingencies would look like.